Lines in Pleasant Places
By Bobby Neal Winters
Lord, you alone are my portion and my cup;
you make my lot secure.
The boundary lines have fallen for me in pleasant places;
surely I have a delightful inheritance.
I will praise the Lord, who counsels me;
even at night my heart instructs me.
--Psalms 16:5-7, NIV
It is rumored that deep within the Ozarks there is a place where those interested go to learn the art of making moonshine. It is called the Moonshine Academy. Every year a new class of students enter the academy, but not everyone decides to come back the following year. The proprietors of the Academy are concerned about this because their aim is spread the art of moonshine making as far and wide as possible. Those who leave the Academy tend to become Revenuers. They would like to know whether there might be a way to tell ahead of time which of their new students might be at risk of becoming Revenuers.
When each student comes to MA, a record is made of the length of their beards and the number of missing teeth. The proprietors wish to make predictions based on those two characteristics, having noted that those who have become successful as moonshiners have certain standards with respect to them.
Some Math
There are two groups, those who succeed and those who don’t. Call the group that succeeds the Elect and denote them by E. We will denote the rest by R, for Revenuer. We will begin the discussion by assuming a simpler situation than what we have and supposing there is only one characteristic or, to use the standard nomenclature, random variable to measure. Call it X.
Random variables are functions that take values on populations. We will write X|E for X restricted only to members of the Elect and X|R for X restricted only to revenuers. We hope that we won’t be piling on too much notation if we let mean(X|E) denote the mean of X for members of the Elect and let mean(X|R) be the mean of X for members of the Revenuers.
Suppose that we find mean(X|R)
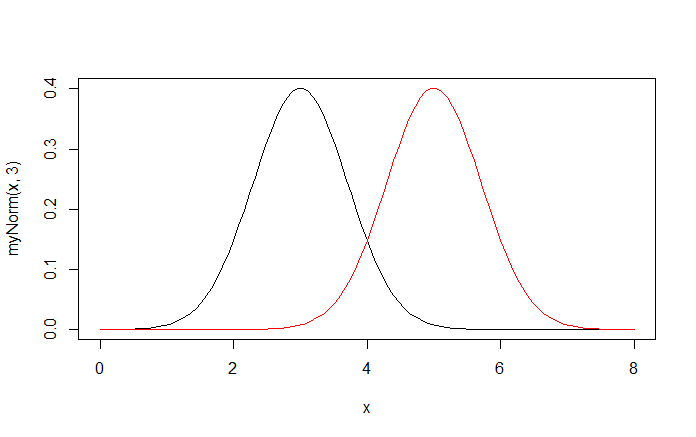
In the figure, we note mean(X|R)=3 and mean(X|E)=5.
In our dreams, we want a magic number C (for cutoff). Say a student named Maynard walks in and his random variable is X(Maynard). We would like to be able to say that if X(Maynard)> C, then Maynard would be one of the Elect and if X(Maynard)
As Yogi Berra said, “Predicting is hard, especially about the future.” In making making a prediction about Maynard’s future, using only the value of X(Maynard), a procedure would be to simply let this magic number C be the midpoint between mean(X|E) and mean(X|R), respectively, and predicting using the method described above, with the realization that you are going to be wrong some of the time.
This is the same as saying predicting Maynard to be in the group E if X(Maynard) is closer to the mean of X on E than it is to the mean of X on R and to be in R otherwise.
Some More Math
Recall that the folks at the Moonshine Academy had two random variables they kept on each of their students: beard length and number of missing teething. Mathematicians like to abstract, so we can think of each of the students at MA as a point in space and the values of the random variables coordinates for that point. We can then plot them out on an X-Y axis. The results might look like those below:
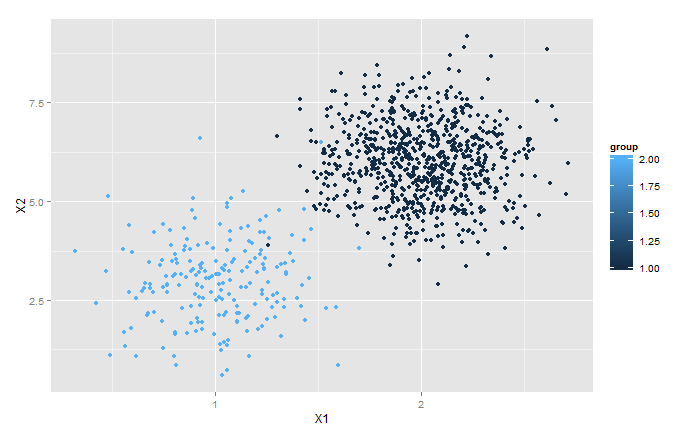
As you see here, the data separates into two groups. There is one in the lower left hand corner that appears to be centered at about (1,1) and another in the upper right that appears to be centered at about (2,2).
Notice that these two groups are more clearly separated on the 2-dimensional plane than either would be if we simply ignored one of the random variables. Ignoring the vertical component, for example, would cause collisions between quite a few members of the two groups and there would be considerably more overlap between the 1-dimensional projections of the two groups.
If only there were some way to rotate the picture so that the line connecting the centers of these two groups so that it aligned with the horizontal.
Even More Math
There is, in fact, a way to perform such a rotation. One could apply a rotation matrix. That’s right, matrices have uses beyond just things to be row-reduced to solve linear systems of equation. Indeed, there real purpose is that of geometric transformation. If you multiply a line by a matrix (by which I mean each point on that line), the result will be either a line or a single point. If the determinant of that matrix is not zero, then the result will always be a line. What is more, if you multiply a parallelogram of area A by a matrix of determinant D, you will get a parallelogram of area DxA. And that’s what determinants are all about. Pretty cool if you ask me.
In this particular case, we probably could get away with multiplying by a rotation matrix that we pick by inspection. However, there is a standard procedure, which we will describe in excruciating detail later, wherein we can obtain the matrix. At this point, let’s pretend we’ve gone gone through it and obtained a matrix M. We then take the a point with coordinates (x1,x2) and put it in the row matrix Y=[x1, x2]. We can then obtain the coordinates of the transformed point as YxM, using matrix multiplication. Applying this to every point gives the picture below:

Note that these two blobs are fairly well separated. One could simply forget about the vertical component and project the points onto the horizontal axis in order to go through the procedure described at the first of this article.
I like to think of the groups in the above picture as spongy clouds. They have centers that you can obtain simply by taking the averages of all the of coordinates of each. The centers of the groups above are exactly the same as the rotated versions of the centers of the groups in the previous picture.
The Process from Thirty-thousand Feet
I am now going to give you the big picture by telling a few lies. Later in the article, if you are still awake, I will provide as many details as I can.
Suppose that a new student comes to seek admission to the Moonshine Academy. The folks at the Admissions Office will measure his beard and count the number of teeth his as missing. (Sometimes they will count the number of teeth he has and subtract that from 32 because it is easier, but I digress.) They will then measure the distance between that point and the centers of the two groups. The student will be associated with the group to whose center he is closer. That is if he is closer to the center of the Elect group he will be predicted to be Elect; if he is closer to the center of the Revenuer group he will be predicted to be a Revenuer.
The word predicted is very important in the paragraph above. Predictions can be wrong. Indeed, even when you use a procedure on data where you know the answers, some of the predictions will be wrong. For example, for the data above we get the following table:
Predicted
| ||
Actual
|
E
|
R
|
E
|
799*
|
1
|
R
|
2
|
198*
|
This says that my model predicted 801 (799 + 2) be in the Elect; of these 799 were but two actually flunked out and became Revenuers. It predicted 199 (1+198) to become Revenuers. The model was right in 997 (799*+198*) of its predictions for its founding data. (That is why those numbers are marked with a *.) These are incredibly good results and this will certainly not be the case with all data sets.
What Happened to the Rotation?
You might have noticed that I’d made a big deal about rotating the matrices to better see how nicely separated the groups were along the horizontal axis, but when I described the process the groups weren’t actually rotated. This is because you don’t have to rotate for the test. The rotation does not change the distances. What would be the closest center in the rotated picture would be closest in the unrotated picture.
However, once the initial test is run and you want to make predictions about candidates for next year it is more convenient to have a formula. For the data above the formula would be: f(bl,mt)=0.982*bl+0.188*mt. Here, bl=beard length and mt=missing teeth. It is easier to determine whether f(bl,mt)>2.330 than it would be to calculate the distance to each of the centers of the groups.
And, as a student who would want to look good with respect to these standards, it is easier to tell that you’d be best advised to spend your time growing your beard as opposed to pulling your teeth.
How Do We Get That Formula?
To get to that formula, we must enter into the jungle of matrices where many enter and few emerge unchanged.
The first matrix I want to introduce you to is the covariant matrix. There is far more to know about it than what I am going to tell you. This is how you get a covariant matrix. Let X be a matrix each of whose columns are values of a random variable. So column one will contain the beard length of each of our students and column two will contain the number of missing teeth of the same student. If you have more random variables to study, you will have more columns. For us, with the beard lengths and the missing teeth of 1000 students, we have X as a 1000x2 matrix.
Now, calculate the mean of each column and subtract that number from each of the columns. Call this new matrix Y. So each element of Y will be the difference between the value of a particular random value for a particular student and the mean of that random variable for all the students. Now the covariant matrix of X, cov(X), is transpose(Y)*Y. For us it will be a 2x2 matrix. Note that cov(X) is symmetric; it is important.
Now, forget about this particular matrix because we are not going to use it, but remember how we got it.
Let XE be the data for the Elect and let XR be the data for the Revenuers. Let pE be the proportion of the data that is from the Elect and pR be the proportion from the Revenuers. Let Sw=pE*cov(XE)+pR*cov(XR). Note that Sw is symmetric; it is important.
Now remember that first matrix X, the one I told you to forget about. We are going to fix it. Instead of being the value of the random variable minus the mean whole column, let it mean of the column for the data group minus the mean of the whole column. That is to say if the student from row i is in the Elect, his entry in the Beard Length column will be the average beard length for the Elect minus the average beard length for everybody. Then Sb=cov(X). Note that Sb is a symmetric matrix; this is important.
Now let M=inverse(Sw)*Sb. Inverse(Sw) is symmetric so M is symmetric. This is important. Write it on your hand with a sharpie.
We are about to digress.
Eigen What?
A discussion of eigenvalues and eigenvectors would take us too far afield. One or more of us would be dead by the time I finished. Suffice it to say that the theory is beautiful in the same way the Arctic is: The beauty is real, but seeing it face to face comes at a cost.
It is enough for us to know the following. If M is a symmetric matrix, and it is, then there is a matrix P and a diagonal matrix D such that M=transpose(P)*D*P. Furthermore, the matrix P will consist of the eigenvectors of M, whatever the hell they are, and the diagonal entries of D will be the eigenvalues of M, whatever the hell they are. Take the eigenvector corresponding to the eigenvalue of largest absolute value and multiply it by the coordinates of the student, and you have your formula. For us that is [bl , mt] * transpose([0.982, 0.188]). To get the critical point C, one applies this formula to the midpoints of each of the groups, and takes the average of the two.
References
“Linear Discriminant Analysis-A Brief Tutorial,” S. Balakrishnama and A. Ganapathiraju, Institute for Signal and Information Processing
Discriminant Analysis, William. R. Kleka, A Sage University Paper, Series: Quantitative Applications in the Social Sciences, 1980




